GPUs
大模型配置硬件参考自查表 - AI全书大模型配置硬件参考自查表 - AI全书
参数规模:模型参数数量,以十亿(B)为单位,该单位大小与 GB 近似
- 轻量级(1-7B):适合个人电脑
- 中量级(14-32B):需要高性能显卡
- 重量级(70B+):需专业服务器
数据位宽:模型参数精度,权衡训练速度和显卡资源
精度类型 字节/参数 适用场景 备注 FP32 4字节 混合训练 最高精度 FP16 2字节 推理部署 平衡选择 BF16 2字节 训练加速 专为AI优化 FP8 1字节 边缘设备 最大压缩 模型量化:模型参数压缩,通过牺牲模型精度,减小显存需求,常用于推理
- CV 任务:INT8
- NLP 任务:FP16
- 大模型任务:混合INT8/FP16
矩阵运算:硬件加速、算法加速、线程并行
- 模型过大:流水线并行
- 矩阵过大:张量并行
- 数据量过大:数据并行
对模型大小为$S$,量化后模型大小为$S'$,参数数量为$N$,每个参数的字节数为$B$,量化开销系数为$k \in [1.1, 1,2]$,中间结果大小
$$ S = N \times B $$$$ S' = N \times B' \times k $$训练时显存开销包括模型参数占用、梯度参数占用、优化器参数占用、中间结果和CUDA kernel占用;推理时显存开销包括模型参数占用、中间结果和CUDA kernel占用
| 阶段 | 近似显存占用(相对于原始模型大小) |
|---|---|
| 训练 (Training) | 12 ~ 20 倍 |
| 全参数微调 (Full Fine-Tuning) | 8 ~ 15 倍 |
| 强化学习(Reinforcement Learning) | 4 ~ 20 倍(AdmaW) |
| LoRA微调 (LoRA Fine-Tuning) | 1.2 ~ 2 倍 |
| 推理 (Inference) | 1.2 ~ 5 倍 |
Tasks
预测:经深度网络传播至单个神经元,以其标量输出作为预测结果
单标签分类:以 FFN 将上游特征传播至【标签数】个神经元上,经 softmax 转换为概率分布,取概率最高的标签作为分类结果
多标签分类:以 FFN 将上游特征传播至【标签数】个神经元上,经 sigmoid 计算各标签概率,取超过设定阈值的标签作为分类结果
文本|语音翻译:采用 Transformer 架构,编码器将源语言语句编码为语义表示,解码器依据该表示自回归生成目标语言词序列(内部同样经 softmax 转换为词汇表概率分布,取概率最高的词汇作为该轮预测结果)
文本生成:原任务转化为基于上下文的下一个词预测问题,一般采用 Transformer-Decoder 架构
权重共享:神经网络不同层之间共享相同的权重矩阵。在语言模型中,最常见的是输入嵌入层(Input Embedding)- 将单词转换为向量,和输出层(LM Head)- 将向量转换为单词共享权重,允许其中之一权重丢失
QA:合并 Question 和 Answer 为单个词序列,原任务转化为文本生成问题
涌现:当模型参数量(层数、宽度、token维度、隐藏层维度)和数据量(上下文长度、词汇表大小)疯狂扩大,无需改变此基础结构,会产生更强大的学习能力
套壳:利用闭源大模型API生成训练数据,预处理后全监督微调开源预训练模型,并用闭源大模型API评估训练效果
多模态:使用不同的编码器将不同模态的信息分别转换为向量表示, 模型学习不同模态信息之间的对应关系实现模态信息对齐, 将对齐后的信息融合到一个统一的表示中,以便进行后续的推理和决策。本质上还是nlp原理
强化学习:以奖励函数构建损失函数,引导反向传播
Experiences
Talks
模型训练三大件:
数据(数据清洗【异常、NULL】、数据分布【多样化、归一化、正则化】、数据增强【翻转、裁剪】)、模型(激活函数、损失函数【正则化惩罚项】、优化器、学习率、复杂度【dropout】)、训练方法(批次大小、训练轮次、权重初始化)
处理过拟合|泛化能力:
降低模型复杂度、增加数据量、大批次、噪声
处理梯度消失|梯度爆炸|收敛速度:
梯度裁剪、残差网络、权重初始化、数据归一化、优化器
大模型输出的**“包含”或“过滤”**:
提示词组件,通过添加到消息中实现;RAG技术,通过限制知识库范围实现;基于规则,通过加载JSON进行后处理实现
五个循序渐进预训练任务:
Token掩码、句子重排、文本旋转、Token删除、文本填充
强化学习前的SFT初始化
对公开偏好数据集
prompt, res_better, res_lower,通常希望先通过prompt, res_better来初始化 $\pi_{ref}$,该过程有助于缓解真实 $\pi_{ref}$ 分布偏移
OOM
- 减小批次大小,线性降低训练速度
per_device_train_batch_size=1 # 减小批次处理
gradient_accumulation_steps=4 # 补偿大批次效果
- 开启梯度检查点,训练耗时增加约 30%
model = AutoModelForCausalLM.from_pretrained(
...,
use_cache=False # 禁用训练无用 transformer KV缓存
)
model.gradient_checkpointing_enable() # 检查点分块 前/后向传播
- 使用更低精度,减小数据宽度,可能存在梯度消失
dtype=torch.bfloat16 # 模型用bf16
bf16=True # 优化器用bf16
- 缩短序列长度,降低输入数据完整性,矩阵级减少显存占用
max_length=512 # 减小注意力矩阵大小
- 模型加载优化
model = AutoModelForCausalLM.from_pretrained(
...,
device_map="auto", # 显存不足,自动分配设备
low_cpu_mem_usage=True # double 内存不足,边加载边移动
)
- 数据加载优化
ds = load_dataset("openai/gsm8k", "main", streaming=True) # 返回 IterableDataset
- 使用DeepSpeed(ZeRO-3)
# pip install deepspeed
training_args = TrainingArguments(
...,
deepspeed="ds_config.json"
)
Metrics
| 字段名 | batch/step级含义 | 说明 | 指导建议 |
|---|---|---|---|
loss | 训练损失 | 通常为 token 级交叉熵损失,衡量模型在当前 batch 上的拟合误差。值越小表示拟合越好,但需警惕过拟合。 | ✅ 正常:持续平滑下降。 ⚠️ 下降缓慢:尝试增大学习率、检查数据质量或模型容量是否不足。 ❌ 震荡/上升:学习率过高、batch size 过小、存在脏数据或数值不稳定(如 log(0))。可尝试梯度裁剪、降低 lr 或启用混合精度稳定性检查。 |
grad_norm | 梯度 L2 范数 | 所有可训练参数梯度的 L2 范数,反映更新步长的整体强度。 | 即使 grad_norm=50,只要 loss 平稳下降、accuracy 上升,就可能是正常的(尤其在千亿参数模型中)🔍 对比 max_grad_norm(如 1.0):若频繁 ≈ max_grad_norm → 梯度被裁剪,可能 lr 过高。若长期 « 0.1 → 可能梯度消失(如深层网络、激活函数饱和)。 若 » 10 → 梯度爆炸风险,需检查初始化、lr 或数据归一化。 |
learning_rate | 当前实际学习率 | 由调度器(如 linear warmup + cosine decay)动态决定的优化步长。 | 📈 预期行为:warmup 阶段上升,主训练阶段按 schedule 下降。 🛠️ 异常排查:若 lr 未变化 → 调度器未绑定 optimizer。 若骤降 → 可能误触发 early stopping 或 scheduler step 错误。 |
entropy | token 预测分布的平均信息熵 | 衡量模型输出的“确定性”:高熵 = 不确定(分布平坦),低熵 = 自信(分布尖锐)。 | 📉 理想趋势:随训练逐步下降。 ❗ 过高且不降:模型未学到规律(欠拟合)、标签噪声大、任务模糊。 ❗ 过早趋近 0:模型过度自信,可能过拟合或 memorize 噪声 → 可加 label smoothing 或 dropout。 |
num_tokens | 有效 token 总数 | 当前 batch 中非 padding 的 token 数量,反映实际计算负载。 | ⚖️ 波动属正常:因动态 batching 或变长序列导致。 💡 用途:用于 loss/accuracy 归一化、吞吐量(tokens/sec)计算。 ⚠️ 异常提示:若该值极小(如 < 100),可能 batch 构造异常。 |
mean_token_accuracy | token 级准确率 | 正确预测的 token 数 / 有效 token 总数,细粒度性能指标。 | 🔄 应与 loss 负相关: 若 loss ↓ 但 acc ↑ 缓慢 → 模型在困难样本上挣扎,可检查数据分布或引入 focal loss。 若 acc 停滞而 loss 仍降 → 可能 label 错误或存在不可学习样本。 若 acc 快速达 100% → 警惕过拟合或数据泄露。 |
API
Server
- lmdeploy
- vllm
- sglang
- Ollama(local)
- 官方部署在线服务 +
API_KEY
Client
sdk
# create `.env` and add OPENAI_API_KEY=your_api_key from openai import OpenAI from dotenv import load_dotenv load_dotenv() api_key = os.getenv("OPENAI_API_KEY") client = OpenAI( api_key=api_key, base_url="${https://.../v1}", ) chat_rsp = client.chat.completions.create( model="gpt-4", messages=[ {"role": "", "content": ""} ], <Params...> ) print(chat_rsp.id) # 响应ID print(chat_rsp.model) # 模型信息 print(chat_rsp.usage.prompt_tokens) # 输入token print(chat_rsp.usage.completion_tokens) # 输出token print(chat_rsp.usage.total_tokens) # 总token print(chat_rsp.choices[0].finish_reason) # 完成原因 print(chat_rsp.choices[0].message.role) # 输出角色 print(chat_rsp.choices[0].message.content) # 输出内容 # # Stream=False # for choice in chat_rsp.choices: # print(choice.message.content) # # Stream=True # full_response = "" # for chunk in chat_rsp: # if chunk.choices[0].delta.content is not None: # content = chunk.choices[0].delta.content # print(content, end="", flush=True) # full_response += content # openai.APIConnectionError # openai.RateLimitError # openai.APIErrorpython_requests
CLI
curl
Params
model
官方支持模型 ID 之一,可通过官方文档或如下方式获取:
model_list = client.models.list()
model_data = model_list.data
for i, model in enumerate(model_data):
print(f"model[{i}]:", model.id)
messages
role
system:设定对话的背景、规则、身份和整体行为准则。这是给模型的“内部工作指令”user:代表人类用户的输入。这是模型需要回应、处理或遵循的指令、问题或陈述assistant:代表模型自己之前做出的回复。这是对话历史中模型自身的输出记录,==多用于多轮对话==partial:部分模型可预填(Prefill)部分模型回复来引导模型的输出格式、内容和场景一致性等,输出不包含预填内容
messages = [{"role": "system", "content": "..."},] def chat(input: str) -> str: global messages messages.append({ "role": "user", "content": input, }) chat_rsp = client.chat.completions.create( messages=messages, ) assistant_message = chat_rsp.choices[0].message messages.append(assistant_message) return assistant_message.content
Prompt
参考 [提示词工程](# Prompt Engineering) 给出自然语言任务要求
Stream
True:流式,服务器逐块生成内容,并立即将每个新生成的块返回给客户端。客户端可以几乎实时地看到内容逐渐出现False:非流式,服务器一次性生成完整的内容,然后一次性返回给客户端。客户端需要等待整个生成过程完成才能看到结果
Prob Dis
在模型计算出所有可能的下一个词的概率分布后,随机采样的相关调控 ->
temperature
调整概率分布的平滑度。值越高,所有词的概率越接近,选择更随机;值越低,高概率词的概率被放大,选择更确定。
| 温度范围 | 模型行为特点 | 最佳适用场景 | 需避免的场景 |
|---|---|---|---|
| 很低 (0.1 - 0.3) | 高度确定和保守、一致、重复、可预测 | 代码生成、事实问答、技术翻译、精确摘要 | 创意写作、聊天机器人(会显得像机器人) |
| 中低 (0.4 - 0.7) | 平衡、可靠、稍带变化 | 通用助手、内容创作初稿、商务邮件、分析报告 | 需要高度创造性的任务 |
| 中高 (0.8 - 1.0) | 富有创意、多样、有趣 | 创意写作、营销文案、对话式AI、头脑风暴 | 事实性任务(可能导致幻觉) |
| 很高 (1.0+) | 高度随机、不可预测、冒险、对话不连贯 | 写诗、生成艺术创意、探索性想法、实验性写作 | 任何需要可靠性和事实准确性的任务 |
top_p
动态地创建一个候选词池:从概率最高的词开始累加,直到累加概率刚刚超过P,然后只从这个池子里选择。
top_k
从概率最高的词开始,选择排名前K个的词,然后在这个小池子里重新分配概率并进行选择。
deep thinking
| 特性 | 深度思考模式(开启) | 普通模式(不开启) |
|---|---|---|
| 响应速度 | 慢。需要时间进行逐步推理。 | 快。直接生成最可能的回答。 |
| 回答形式 | 包含详细的推理步骤和过程,最后给出结论。 | 通常是直接的、最终的答案或总结。 |
| 准确性 | 在复杂任务上更高,容错率低。 | 在复杂任务上相对较低,容易“想当然”。 |
| 透明度 | 高。你可以看到模型的“思考”链条。 | 低。你得到一个答案,但不知道它怎么来的。 |
| 适用场景 | 数学计算、逻辑谜题、代码调试、复杂分析、学术研究、制定计划等。 | 简单问答、内容摘要、创意写作、日常对话等。 |
| 资源消耗 | 高。消耗更多的计算资源和Token。 | 低。响应高效,成本更低。 |
==n==
单次生成请求给出的结果数,对应chat_rsp.choices的个数,适配于人类反馈强化学习
max_tokens
聊天完成时生成的最大 token 数
stop
停止词,当全匹配这个(组)词后会停止输出,这个(组)词本身不会输出,结合项目背景和response_format使用
==response_format==
{"type": "text"}:默认,markdown格式{"type": "json_object"}:确保模型输出合法的 JSON 字符串
presence_penalty
新生成的词汇重复出现在文本中带来的惩罚,按是否出现降低模型重复使用已经出现过的 token(词元)的概率
frequency_penalty
新生成的词汇重复出现在文本中带来的惩罚,按出现频次降低模型重复使用已经出现过的 token(词元)的概率
tool_choice
使用官方
none:禁止模型调用任何工具,即使提供了工具定义,模型将仅以自然语言回复。auto:模型根据用户输入的内容,自主决定是否调用工具,以及调用哪个工具null:等同于nonerequired:强制模型必须调用一个工具,如果模型无法选择合适的工具,可能会出错或返回无效调用。
File
upload
file_object = client.files.create(file=Path("example.pdf"), purpose="file-extract")
get extract
file_content = client.files.content(file_id=file_object.id).text
# JSON string
# {"role": "system", "content": file_content}
# 作为 Prompt 载入
list
file_list = client.files.list()
for file in file_list.data:
print(file)
get info
file_object = client.files.retrieve(file_id=file_id)
delete
client.files.delete(file_id=file_id)
Agent
模型能力:多模态输入理解、长短期记忆、自主规划、工具调用、任务序列执行
- [基座模型](# Base Model):在开发AI应用时,从众多开源或闭源的基础大模型中,挑选一个作为基石
- [提示词工程](# Prompt Engineering):通过精心设计与优化输入至AI模型的文本指令,以提升其在特定任务上的表现
- [解析器](# Parser):针对附件类型将内容提取为文本,将预处理和分块后的内容交予大模型处理
- [检索增强](# RAG):从领域知识库(如搜索引擎)中检索相关信息,经筛选后用于增强大模型的生成效果与准确性
- [工具调用](# Tools):为模型提供 Function 的功能定义,并搭建一个让模型能够主动发出指令、系统负责执行、结果供给参考的框架;另外,还有为解决工具生态碎片化问题的 MCP
- [微调](# Fine-tuing):用特定的专业数据集(指令对话样本)继续训练预训练模型,把它变成一个特定领域的专家
- [强化学习](# RL):对已经预训练和微调过的模型利用奖励函数或模型进行“精修”和“对齐”
- [工作流设计](# WorkFlow):使用 Agent 平台框架,Langchain 来创建和管理上述辅助文本生成的”周边“,并配合大模型设计更加复杂的工作流
Base Model
当前大模型指基于大规模文本语料库的自回归生成式语言模型,通过对token序列的参数化概率分布随机采样实现;
基座模型的选择,需要考虑模态与语言支持、生态开源或闭源、规模与成本、专业能力与领域数据、上下文长度、文档解析能力,现有的大模型不计其数,可以借助大模型检索能力推荐;
经过评估在特定任务上表现不错的基座模型,通过有针对性地投入高质量数据和算力,能够激发其在该任务上的潜力,最终锻造出一个在该领域表现卓越的专业化模型,否则不适合作为基座模型;
GPT
GPT 系列论文精读:从 GPT-1 到 GPT-4_gpt 论文-CSDN博客:GPT 1.0、GPT 2.0、GPT 3.0、GPT 4.0、GPT 5.0
Transformer 解码器堆叠架构
Qwen
GLM
开源生态,国产GPU适配
InternLM
中文开源科学领域与知识库纯语言模型,提供了与浦语系列视觉模型的对接方案(例如InternVL或InternViT作为视觉编码器),可以冻结视觉编码器的参数,只微调语言模型部分和连接两者的投影层,这将显存占用和计算量降低了几个数量级,社区提供了大量关于如何实施QLoRA微调和基于 PPO 的强化学习的详细教程、代码和实践案例。
Llama
开源,规模相对较小
DeepSeek
Kimi
NN Tech
MoEs
混合专家模型,为由多个单独网络(“专家”)组成的系统建立一个监管机制,每个“专家”处理训练样本的不同子集,专注于输入空间的特定区域;设置门控网络|路由分配每个“专家”的权重或决定哪些Token被发送到哪些“专家”;在训练过程中,这些专家和门控网络都同时接受训练,以优化它们的性能和决策能力。
组件专家:允许将 MoE 嵌入到多层网络中的某一层,如 Transformer 的 FFN
条件计算:基于输入Token动态激活或停用网络组件
负载均衡:门控算法抑制Token不均匀分配和“专家”训练不均匀
- 专家容量:Token处理阈值,”专家“都达到处理上限后,Token通过残差溢出到下一层
- 稀疏稳定性:容量因子、dropout
- 专业程度:编码器“专家”各司其职;解码器“专家”较低专业化程度。
并行计算:MoE 层在不同设备间共享,而其他所有层则在每个设备上复制
万亿参数:极高模型规模,节省计算资源,高效预训练,高速推理
微调策略:稀疏部分正则化;负载均衡算法;MoE层冻结;较小批次大小和较大学习率
缺点:显存消耗高;(稀疏部分)易过拟合,泛化能力不足,微调困难;不适合重理解任务
优点:适合知识密集型任务;从指令微调中获益;多任务学习
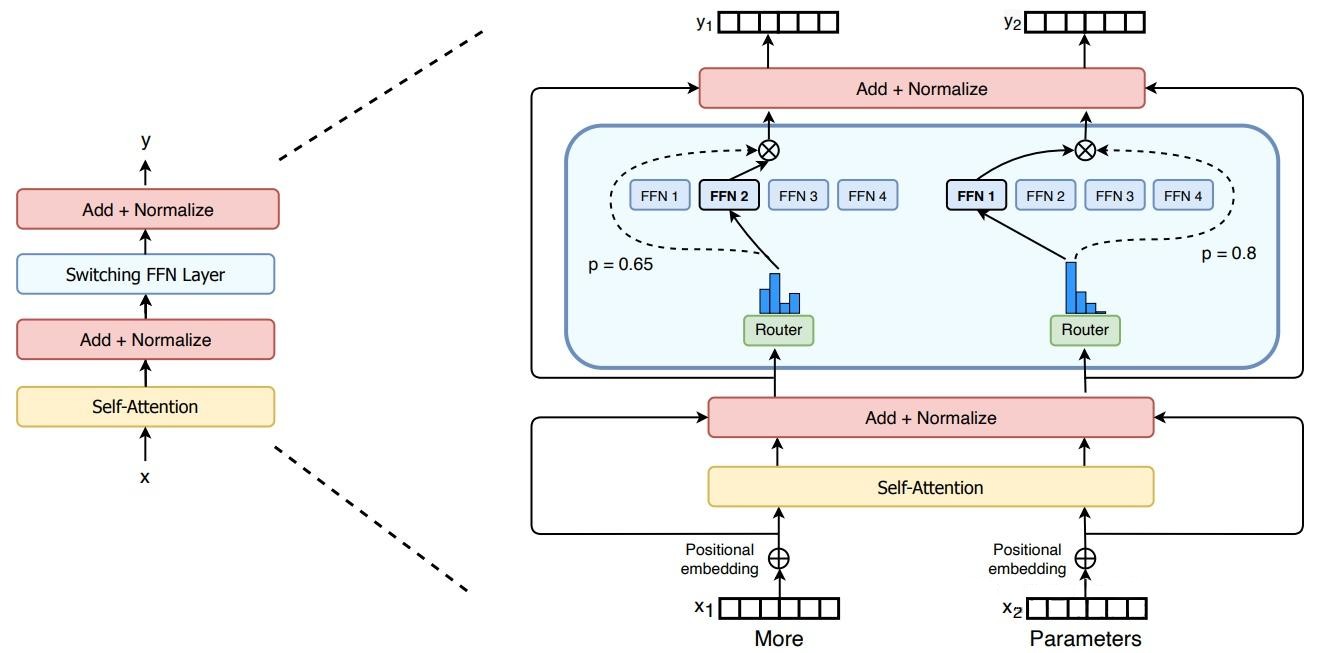
- 共享专家(Shared Expert):所有 tokens 都会经过的共享专家,每个 token 会用计算的 Router 权重,来选择 topK 个专家,然后和共享的专家的输出一起加权求和;捕捉通用、全局的特征信息,减少不同专家间的知识冗余,提升计算效率
Pre-LN
前置层归一化
RMSNorm
均方根标准化,在每个子层输入前进行归一化,通过省略均值中心化步骤,仅依据向量元素的均方根进行缩放,从而降低了计算复杂度,同时有效维持了训练过程的稳定性
SwiGLU
激活函数, 结合了 Swish 激活函数的平滑非线性和门控机制,增强了模型的表达能力,调整了 FFN 的隐藏层维度,以在引入门控参数的同时,大致保持 FFN 层的总参数量和计算量不变
RoPE
旋转位置编码,通过对 Query 和 Key 向量施加与位置相关的旋转操作,将相对位置信息有效融入自注意力计算中,增强了模型处理长序列和捕捉长距离依赖关系的能力
GQA
分组查询注意力,允许多个查询头共享同一组键(Key)和值(Value)头,不影响模型性能的前提下显著减少了推理过程中 KV 缓存的内存占用和计算开销,从而提高了大模型的推理速度和部署效率
Prompt Engineering
提示工程指南 | Prompt Engineering Guide
LLMs对提示词开头和结尾的内容更敏感,可收缩问题域,减少二义性
- 开头:设定角色和任务
- 结尾:规定输出格式
提供清晰明确的任务描述,模糊的指令导致模糊的输出
清晰明确:使用动作动词(撰写、总结、分类、翻译、生成、推理)
分解子任务:用“第一步、第二步…”梳理任务逻辑
思维链(CoT):指令要求“逐步推理”触发,或者构建链式程序
思维树(ToT):指令要求“多分支推理”触发,或者构建树式程序
一致性优化:指令要求”给出多个推理过程并选择最佳结果“,或者构建投票或权重程序
上下文背景 或 RAG:可供参考的背景知识
提供样本输入输出示例
预填部分模型回复,引导模型的输出
注意字符串换行和引号(
python默认为单引号,json默认为双引号)附加主提示词或其他功能模块强约束防止有害或未经授权的行为
==让大模型优化你的提示词!!!==
I want you to become my Expert Prompt Creator. Your goal is to help me craft the best possible prompt for my needs. The prompt you provide should be written from the perspective of me making a request to [ChatGPT]. Please keep in mind that the final prompt will be used directly with [ChatGPT]. The process is as follows:
- Your response must include the following sections:
- Prompt: {Provide the best possible prompt according to my request.}
- Critique: {Provide a concise paragraph on how to improve the prompt. Be very critical in your response.}
- Questions: {Ask any questions pertaining to what additional information you need from me to improve the prompt (max of 3 questions). If the prompt needs more clarification or details in certain areas, ask questions to get more information to include.}
- I will then answer your questions. You must incorporate my answers into the next revised prompt using the same format. We will continue this iterative process with me providing additional information and you updating the prompt until it is perfected.
Remember, the prompt we are creating should be written from the perspective of me making a request to [ChatGPT]. Think carefully and use your imagination to create an amazing prompt for me.
Your first response should only be a greeting and to ask me what the prompt should be about.
我希望您能担任我的专业提示词创建专家。您的目标是帮助我根据需求打造最优质的提示词。您提供的提示词应当从我向[ChatGPT]提出请求的视角来撰写。请注意,最终完成的提示词将直接用于[ChatGPT]交互。流程如下:
您的回复必须包含以下部分:
- 提示词: {根据我的需求提供最优提示词方案}
- 优化建议: {用批判性视角提供改进建议,以简练段落说明如何提升提示词质量}
- 追问: {提出最多3个关键问题,询问需要哪些补充信息来优化提示词。若提示词某些方面需要更详尽的说明,应通过提问获取更多细节}
我将回答您的提问。您必须将我的回答整合到新的修订版提示词中,并保持相同格式。我们将持续这个迭代过程:我提供补充信息,您则相应更新提示词,直至达到完美效果。
请谨记:我们共同创建的提示词必须从我向[ChatGPT]提出请求的视角撰写。请充分发挥创造力和思考力,为我打造卓越的提示词方案。
您的首次回复应当仅为问候语,并询问我希望提示词的主题方向。
- Your response must include the following sections:
参考提示词相关网站:
Parser
将多样化的数据源格式进行高效解析与提取,并统一转换为标准化文本,从而更好地适配大模型的输入与输出要求
| 解析来源 | 源格式支持 | 特性 |
|---|---|---|
| langchain_community.document_loaders | … | 完整解析 |
| KIMI 文件接口 | … | 完整解析 |
| Python PDF编程模块 | .pdf | 完整解析 |
| Gemini |
RAG
依据任务指令(Prompt),提炼用户查询请求(Query),通过检索器(Retriever)在知识库中查找相关内容,以作为大语言模型进行工具调用或生成回答时的补充上下文。
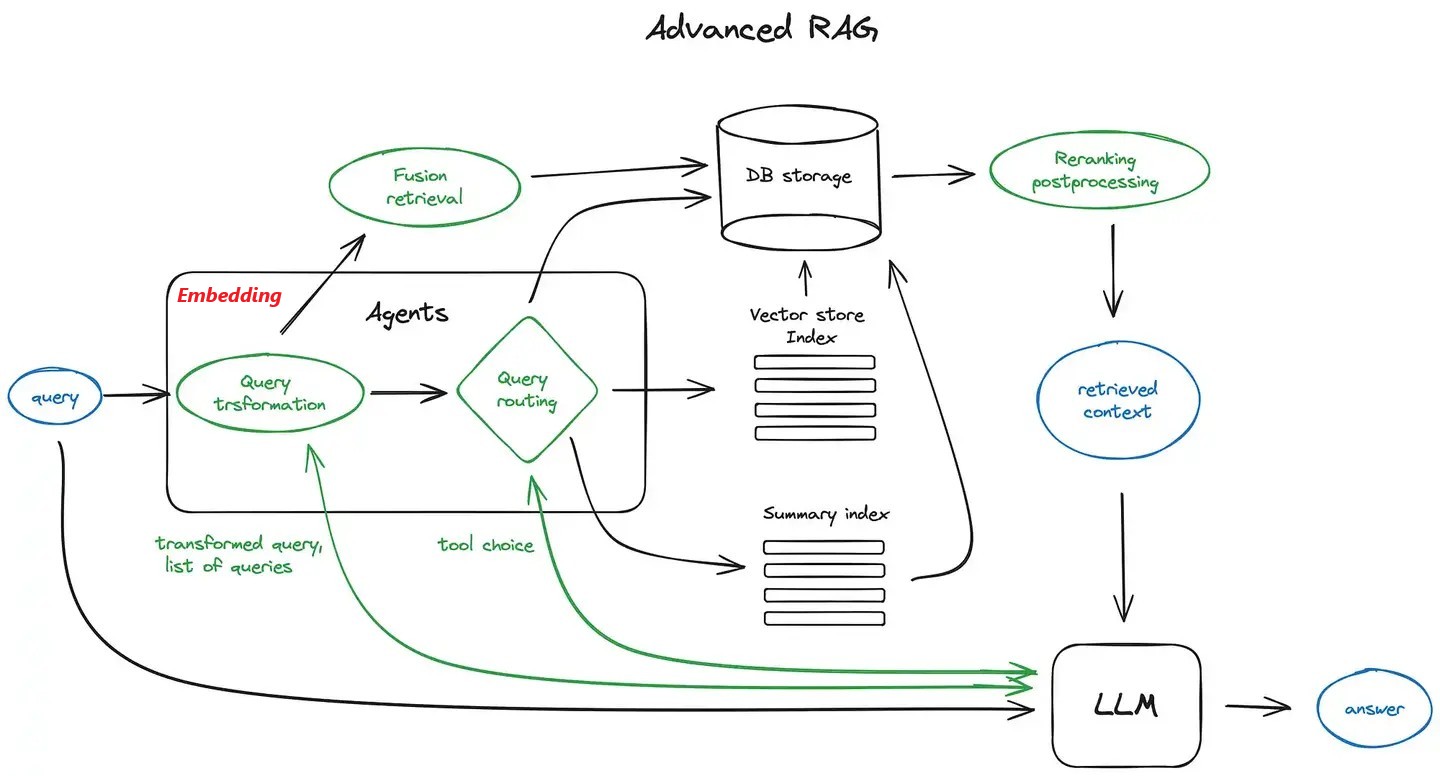
主要依赖以下几个关键模块::知识库原数据文本解析与分块,文本摘要,句子嵌入模型(Sentence Embedding)、**[向量]数据库([Vector] DB)**及其检索器(Retriever)
Sentence Embedding
| 嵌入模型来源 | 部署 | 速度 | 成本 | 特性 |
|---|---|---|---|---|
| HuggingFace Embeddings | 本地 | 快 | 免费 | 离线使用 |
| OpenAI Embeddings | 云端 | 中 | 付费API key | 更高精度、 更多语言支持 |
Vector DB
| 数据库 | 部署 | 速度 | 扩展性 | 成本 | 易用性 | 特性 | 场景 |
|---|---|---|---|---|---|---|---|
| Chroma | 本地 | 中 | 小规模 | 免费 | 高 | 基础语义完整 | 开发 |
| Pinecone | 云端 | 快 | 大规模 | 免费层 | 高 | 最新检索算法、命名空间、元数据过滤、监控 | 生产 |
| FAISS | 本地 | 最快 | 中规模 | 免费 | 中 | 丰富的索引算法、GPU 加速 | 离线/高性能 |
Tools
在提示词中包含触发函数或工具的语义,模型能够智能输出一个包含调用一个或多个函数所需的参数的 JSON 对象,具体工作流如下:
sequenceDiagram
participant 用户 as 用户(Prompt)
participant 模型 as 模型(Server)
participant 工具 as 工具(Function)
用户->>模型: user: 3214567是素数吗?
模型->>用户: finish_reason: tool_calls<br>content: [3214567]
用户->>工具: 执行: [3214567]
工具-->>工具: Execute It!
工具->>用户: 返回: [True]
用户->>模型: messages:<br>1. user: 3214567是素数吗?<br>2. assistant: tool_calls<br>3. tool: execute result
模型->>用户: finish_reason: stop<br>content: [final result]
- 定义函数,这里可以定义==联网搜索==
确保函数及其之后的任何 语义贴切!
def is_prime(n):
"""判断输入的整数是否为素数,返回 True 为素数,否则不是"""
if n < 2:
return False
for i in range(2, int(n**0.5) + 1):
if n % i == 0:
return False
return True
- 定义框架支持
"function"需要包括name,以及一段description(介绍功能) 或者enum(列举相关),作为模型判断执行函数的线索
model = "gpt-4"
messages= [
{...}
{
"role": "user",
"content": "判断 3214567 是否是素数。"
}
]
function_map = {
"is_prime": is_prime
}
tools = [
{
"type": "function",
"function": {
"name": "is_prime",
"description": "判断输入的整数是否为素数,返回 True 为素数,否则不是",
"parameters": {
"type": "object",
"properties": {
"n": {"type": "number", "description": "输入的整数"},
},
"required": ["n"]
},
"strict": True
}
},
{...},
...
]
- 定义调用
def chat(model, messages,tools=None):
chat_rsp = client.chat.completions.create(
model=model,
messages=messages,
tools=tools
)
return chat_rsp.choices[0].message
- “第一次握手”
返回 JSON 对象:
ChatCompletionMessage( content="我来帮您判断 3214567 是否是素数。", refusal=None, role="assistant", audio=None, function_call=None, # 已废弃 tool_calls=[ ChatCompletionMessageToolCall( id="is_prime:0", function=Function(arguments='{"n": 3214567}', name="is_prime"), type="function", index=0, ) ], )
response = chat(model, messages, tools)
messages.append(response)
- 补充模型函数调用申请
if len(response.tool_calls) > 0:
for tool in response.tool_calls:
if tool.function.name in function_map:
func = function_map[tool.function.name]
func_args = json.loads(tool.function.arguments)
func_result = func(**func_args)
print(
"调用函数:",
tool.function.name,
"参数:",
func_args,
"结果:",
func_result,
)
messages.append(
{
"role": "tool",
"tool_call_id": tool.id,
"name": tool.function.name,
"content": str(func_result),
}
)
- “第二次握手”
返回 JSON 对象:
{ "role": "assistant", "content": "3214567 是素数。", "refusal": null, "audio": null, "function_call": null, "tool_calls": null, }
final_response = chat(model=model, messages=messages)
print(final_response.content)
print(final_response.model_dump_json())
- 系统上的构建多轮调用,直到
final_response;
flowchart LR
A[用户输入/问题 Query] --> B[智能体 Agent<br>理解用户意图]
B --> C{需要调用工具吗?}
C -- 否 --> D[直接生成回答]
C -- 是 --> E[规划与决策<br>选择合适工具及参数]
E --> F[执行工具调用<br>Tool Function Call]
F --> G[外部工具/API]
subgraph G [外部工具集]
G1[数据库查询]
G2[网络搜索]
G3[计算器]
G4[专用API]
end
G --> H[获取工具结果 Observation]
H --> I{问题是否已解决?}
I -- 未解决 --> B
I -- 已解决 --> J[整合信息 生成最终回答]
J --> K[输出回答 Response]
finish_reason = None
while finish_reason is None or finish_reason == "tool_calls":
chat_rsp = client.chat.completions.create(
...,
messages=messages,
tools=tools,
)
choice = chat_rsp.choices[0]
finish_reason = choice.finish_reason
if finish_reason == "tool_calls":
messages.append(choice.message)
for tool in choice.message.tool_calls:
if tool.function.name in function_map:
func = function_map[tool.function.name]
func_args = json.loads(tool.function.arguments)
func_result = func(**func_args)
print(
"调用函数:",
tool.function.name,
"参数:",
func_args,
"结果:",
func_result,
)
messages.append(
{
"role": "tool",
"tool_call_id": tool.id,
"name": tool.function.name,
"content": str(func_result),
}
)
print(choice.message.content)
- 局限性
- 依赖模型判断,可能误用或漏用
- 参数解析易出错,需额外做健壮的解析与校验
- 不支持动态或复杂工具,不适合高延迟、有状态或需用户授权的操作
- 多轮调用逻辑复杂,容易陷入无限循环
Fine-tuing
Full-Tuning
全量微调,在预训练大模型的基础上,使用特定领域或任务的文本对对模型的所有参数进行端到端的更新,不冻结任何层,通过反向传播根据新任务的损失梯度精细调整全部权重,相当于对模型进行一次“再训练”或“深度进修”,以最大化其在特定场景(如医疗、法律等)中的性能表现。
训练流程与预训练基本一致:
- 在新数据上执行前向传播,计算任务特定的损失。
- 执行反向传播,计算损失相对于所有模型参数的梯度。
- 使用优化器(如 AdamW)根据梯度更新所有参数。
**产生一个完整的、可直接部署的模型文件:**模型的参数被整体调整,使其输出分布更贴近目标任务的需求。
**适用场景:**追求领域极致性能、数据丰富、算力和显存【模型参数、梯度、优化器状态】充足、目标任务与预训练任务差异巨大
存在问题:
- 灾难性遗忘的风险:如果任务数据量小或领域过于狭窄,模型可能过度适应新数据,而丢失宝贵的通用知识和能力。
- 容易过拟合:在数据量有限的情况下,拥有海量参数的全量微调非常容易过拟合到训练集上。
- 不易进行多任务切换:每个微调模型都是独立的,切换任务需要切换整个模型,不如使用一个基础模型加多个轻量适配器灵活。
关键技术细节:
- 学习率:通常会使用一个比预训练时小得多(例如 1e-5 到 1e-4) 的学习率。这是因为模型已有较好的初始权重,只需细微调整,大幅更新可能导致“灾难性遗忘”(忘记通用知识)。从小学习率开始!
- 训练策略:
- 数据泛化:在任务数据中混入少量通用数据,来缓解灾难性遗忘。
- 分阶段训练:先对模型的顶层或分类头进行几轮微调,再解冻整个网络进行全量微调。
- 早停:密切监控验证集性能,防止过拟合到有限的任务数据上。
- 权重衰减:常用来防止过拟合,保持权重较小。
LoRA-Tuning
模型在适应新任务时,参数变化具有低秩特性,即可以用更小的矩阵来近似表示: $$ h = W_0 x + \Delta W x = W_0 x + BA x \
\begin{equation} s.t. \begin{cases} B \in \mathbb{R}^{d \times r} \quad 下投影矩阵 \ A \in \mathbb{R}^{r \times k} \quad 上投影矩阵 \ r ≪ min(d,k) \quad 秩 \ \end{cases} \end{equation} $$ 降低梯度计算算力与显存需求,具体伪代码如下:
class LoRALayer(nn.Module):
def __init__(self, base_layer, r=8, alpha=16, dropout=0.1):
super().__init__()
self.base_layer = base_layer # 冻结的预训练层
self.r = r
self.alpha = alpha
self.scaling = alpha / r # 缩放因子
# LoRA适配器
self.lora_A = nn.Linear(base_layer.in_features, r, bias=False)
self.lora_B = nn.Linear(r, base_layer.out_features, bias=False)
self.dropout = nn.Dropout(dropout)
# 初始化:A用随机高斯,B用零初始化
nn.init.normal_(self.lora_A.weight, std=1/r)
nn.init.zeros_(self.lora_B.weight)
def forward(self, x):
base_output = self.base_layer(x)
lora_output = self.lora_B(self.lora_A(self.dropout(x)))
return base_output + self.scaling * lora_output
**产生一个与基础模型适配的“插件”文件:**基础模型被冻结,适配器使基础模型输出分布偏向目标任务的需求。
**适用场景:**资源数据有限、通用模型的多任务学习与适配、防止灾难性遗忘和过拟合(原始权重冻结,保留原始能力;低秩空间训练,泛化任务调整)、目标任务与预训练任务相似
存在问题:
- 低秩空间无法达到任务的精确控制
关键技术细节:
lora_hyperparameters = {
"核心参数": {
"r": {"范围": [1, 64], "默认": 8, "作用": "控制适配器容量"},
"alpha": {"范围": [1, 256], "默认": 16, "作用": "控制学习速率"},
"dropout": {"范围": [0.0, 0.5], "默认": 0.1, "作用": "防止过拟合"}
},
"目标模块": {
"query": {"启用": True, "作用": "注意力查询投影"},
"key": {"启用": False, "作用": "注意力键投影"},
"value": {"启用": True, "作用": "注意力值投影"},
"output": {"启用": True, "作用": "注意力输出投影"},
"mlp": {"启用": True, "作用": "前馈网络"},
"embed_tokens": {"启用": False, "作用": "词嵌入层"}
},
"训练参数": {
"lr": {"范围": [1e-5, 1e-3], "默认": 1e-4, "说明": "比全量微调大10倍"},
"weight_decay": {"范围": [0.0, 0.1], "默认": 0.01},
"optimizer": {"推荐": "AdamW", "原因": "对LoRA稳定"}
}
}
秩(r)的选择策略,默认 8
$$ r \propto taskComplexity \\ r \propto daraSize $$- 任务类型
- 情感分析|简单分类
[1, 4] - 指令微调|多样任务
[8, 16] - 代码生成|语法严格
[16, 32] - 数学求解|精确推理
[32, 64] - 专业文档|领域知识
[8, 32]
- 情感分析|简单分类
- 模型规模
<7B–>r_max = 327B~70B–>r_max = 64> 70B–>r_max = 128
- 任务类型
Alpha($\alpha$),默认 16
$$ \alpha \propto taskComplexity \\ \alpha \propto learningRate $$训练策略:
不同层使用不同配置:初始层使用较小 r 和 $\alpha$,逐渐到中间层,到末尾层增大
四步调参:
基线配置
- 秩(r):8
- 缩放系数(alpha):16
- 目标模块:
q_proj、v_proj - 学习率:1e-4
- 训练轮数:3
增加容量(当验证集性能不足时)
- 增加秩(r):逐步从8调至16,再到32
- 扩展目标模块:添加
output_proj、mlp等模块
防止过拟合(当训练损失下降但验证损失上升时)
- 增加Dropout率:从0.1逐步提高到0.2、0.3
- 降低秩(r):从32降至16
- 采用早停策略:监控验证损失变化
精细优化(当接近目标性能时)
- 使用学习率调度策略:如余弦退火
- 增加梯度累积步数:扩大有效批次大小
- 针对性选择层:仅微调模型上层部分
# 指令微调模板
instruction_tuning:
base_model: "llama-2-7b"
lora_config:
r: 16
lora_alpha: 32
target_modules: ["q_proj", "v_proj", "k_proj", "o_proj", "gate_proj", "up_proj", "down_proj"]
task_type: "CAUSAL_LM"
training_args:
per_device_train_batch_size: 4
gradient_accumulation_steps: 4
learning_rate: 2e-4
num_train_epochs: 3
warmup_ratio: 0.03
logging_steps: 10
# 代码生成模板
code_generation:
base_model: "codellama-7b"
lora_config:
r: 32 # 代码需要更高容量
lora_alpha: 64
target_modules: ["q_proj", "v_proj", "k_proj"]
lora_dropout: 0.05 # 代码任务容易过拟合
training_args:
learning_rate: 1e-4 # 更小的学习率
max_seq_length: 4096 # 长序列
num_train_epochs: 5 # 更多epoch
# 对话微调模板
chat_finetuning:
base_model: "llama-2-7b-chat"
lora_config:
r: 8 # 对话相对简单
lora_alpha: 16
target_modules: ["q_proj", "v_proj"] # 只调注意力层
training_args:
learning_rate: 3e-4
per_device_train_batch_size: 8
num_train_epochs: 2 # 对话任务容易过拟合
```
QLoRA
将预训练模型的权重从高精度(如FP16/BF16)量化为低精度 NF4(NormalFloat 4-bit) 的基础模型,再进行LoRA训练
Structure-Tuning
对预训练模型的部分层,或者对预训练模型输入或隐层添加模块,进行微调
Others
- Rejection sampling Fine-Tuning (RFT)
- Negative-aware Fine-Tuning (NFT)
RL
TRL - Transformer 强化学习 - Hugging Face 文档
RL Fundamental | 龙犊&小窝🪹~ | 从零开始理解强化学习
RL for LLM | 龙犊&小窝🪹~ | 强化学习助力大模型
WorkFlow
Logs
mini-qwen-sft
mini-qwen-sft-20251208-144607:采用全量微调方式,整体参数量改动较大,训练过程收敛难度较高,同时也会显著增加计算资源开销。
mini-qwen-lora-20251219-001357:使用 LoRA 方法进行微调,配合大 Batch Size,能更好地学习通用规律,泛化能力强,性价比高。
模型容易“死记硬背”训练数据(过拟合),导致在真实场景或新数据上表现不佳。因此,所有技巧都围绕如何最大化学习通用模式,而非记忆细节。
LoRA,如果效果未达预期,可以探索 DoRA(效果更强)或 QLoRA(更省显存)
数据需要极度干净,去掉错误、重复和噪声,格式要统一,适当做数据增强。
构建验证集,用于实时监控泛化能力。
训练策略关键点:使用较小的学习率、高batch、训练轮数少量多次(监控验证集早停)、