GPUs
大模型配置硬件参考自查表 - AI全书大模型配置硬件参考自查表 - AI全书
参数规模:模型参数数量,以十亿(B)为单位,该单位大小与 GB 近似
- 轻量级(1-7B):适合个人电脑
- 中量级(14-32B):需要高性能显卡
- 重量级(70B+):需专业服务器
数据位宽:模型参数精度,权衡训练速度和显卡资源
精度类型 字节/参数 适用场景 备注 FP32 4字节 混合训练 最高精度 FP16 2字节 推理部署 平衡选择 BF16 2字节 训练加速 专为AI优化 FP8 1字节 边缘设备 最大压缩 模型量化:模型参数压缩,牲模型精度,减小显存需求,用于推理
- CV 任务:INT8
- NLP 任务:FP16
- 大模型任务:混合INT8/FP16
矩阵运算:硬件加速、算法加速、线程并行
- 模型过大:流水线并行
- 矩阵过大:张量并行
- 数据量过大:数据并行
对模型大小为$S$,量化后模型大小为$S'$,参数数量为$N$,每个参数的字节数为$B$,量化开销系数为$k \in [1.1, 1,2]$,中间结果大小
$$ S = N \times B $$$$ S' = N \times B' \times k $$- 训练时显存开销包括模型参数占用、梯度参数占用、优化器参数占用、中间结果和CUDA kernel占用
- 推理时显存开销包括模型参数占用、中间结果和CUDA kernel占用
阶段 近似显存占用(相对于原始模型大小) 训练 (Training) 12 ~ 20 倍 全参数微调 (Full Fine-Tuning) 8 ~ 15 倍 LoRA微调 (LoRA Fine-Tuning) 1.2 ~ 2 倍 推理 (Inference) 1.2 ~ 5 倍
TASKs
- 预测:经深度网络传播至单个神经元,以其标量输出作为预测结果
- 单标签分类:以 FFN 将上游特征传播至【标签数】个神经元上,经 softmax 转换为概率分布,取概率最高的标签作为分类结果
- 多标签分类:以 FFN 将上游特征传播至【标签数】个神经元上,经 sigmoid 计算各标签概率,取超过设定阈值的标签作为分类结果
- 文本|语音翻译:采用 Transformer 架构,编码器将源语言语句编码为语义表示,解码器依据该表示自回归生成目标语言词序列(内部同样经 softmax 转换为词汇表概率分布,取概率最高的词汇作为该轮预测结果)
- 文本生成:原任务转化为基于上下文的下一个词预测问题,一般采用 Transformer-Decoder 架构
- QA:合并 Question 和 Answer 为单个词序列,原任务转化为文本生成问题
- 多模态:使用不同的编码器将不同模态的信息分别转换为向量表示, 模型学习不同模态信息之间的对应关系实现模态信息对齐, 将对齐后的信息融合到一个统一的表示中,以便进行后续的推理和决策。本质上还是nlp原理
- 套壳:利用闭源大模型API生成训练数据,预处理后全监督微调开源预训练模型,并用闭源大模型API评估训练效果
Terms
- 温度(Temperature):控制模型输出随机性与创造性,数值越低(如0.1-0.5),生成结果越确定、保守且可预测,模型倾向于选择概率最高的词汇;数值越高(如0.7-1.0以上),输出越随机、多样且富有创意,模型会赋予低概率词汇更多机会,但可能降低连贯性
- 涌现(Emergence):当模型参数量(层数、宽度、token维度、隐藏层维度)和数据量(上下文长度、词汇表大小)疯狂扩大,无需改变此基础结构,会产生更强大的学习能力
Transformers
| strcture | position | activation | LN |
|---|---|---|---|
| Encoder - Decoder | Sinusoidal | ReLU | Post LN |
| Encoder only | 绝对位置 | GeLU | Pre LN |
| Dncoder only | RoPE | SwiGLU | Post Deep LN |
| Casual Encoder | ALiBi | GeGLU | Pre RMS LN |
| Casual Decoder | |||
| Prefix Decoder |
Transformer
史上最全Transformer:灵魂20问帮你彻底搞定Transformer-干货! - 知乎
CNN像素级全局感知能力(自注意力)、RNN序列建模特性(位置编码),适合seq2seq(context + prompt -> answer)问题 hard train 一发
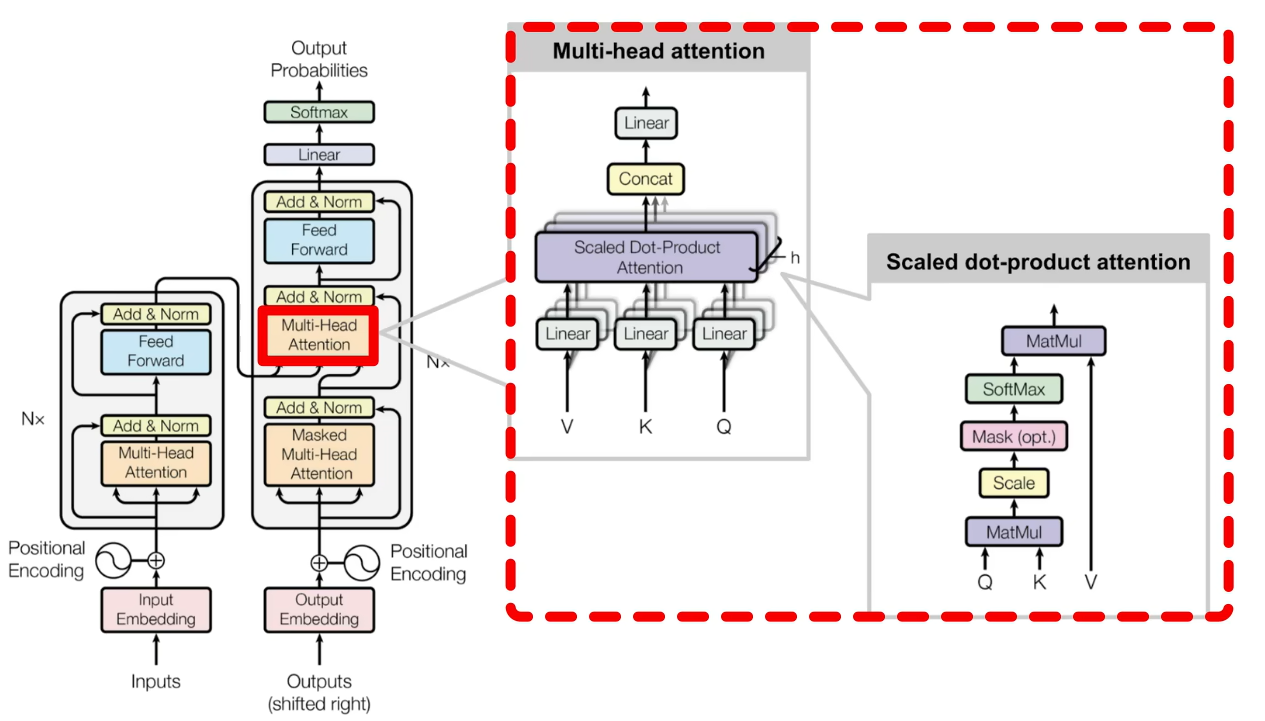
编码器(Encoders):生成带有注意力信息的$\text{Keys}/\text{Values}$向量
- 词嵌入(Token Embedding):根据点积相似度,将离散的词符号映射到$d_{\text{model}}$维向量空间中
- 位置编码(Positional Encoding):向词向量中添加其在句子中先后关系的信息
$$ PE_{(pos, 2i)} = \sin\left(\frac{pos}{10000^{2i/d_{\text{model}}}}\right) \ PE_{(pos, 2i+1)} = \cos\left(\frac{pos}{10000^{2i/d_{\text{model}}}}\right) \
\mathbf{h}_i = \mathbf{e}_w + \mathbf{p}_i $$
自注意力机制(Self–Attention):利用三个线性变换矩阵$\text{W}_q、\text{W}_k、\text{W}_v$将每个词向量映射为$\text{Querys}, \text{Keys}, \text{Values}$向量;再以缩放点积的方式计算不同词向量之间$\text{Querys}$-$\text{Keys}$相似度矩阵;针对每个词向量与其他词向量的相似度,与对应值向量$\text{Values}$求加权和,生成具有注意力分配的新词向量表示。一般地,可以将$Q, K, V$均归纳为原始词向量 $$ \mathbf{Q} = \mathbf{X}\mathbf{W}_Q, \mathbf{K} = \mathbf{X}\mathbf{W}_K, \mathbf{V} = \mathbf{X}\mathbf{W}_V \
\text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^\top}{\sqrt{d_k}}\right)V $$
多头注意力机制(Multi-Headed Attention):并行化多组$\text{W}_q、\text{W}_k、\text{W}_v$注意力头,学习不同投影子空间的特征,将不同头输出拼接起来,维度不发生变化,从而捕获输入序列中不同类型的依赖关系,增强模型的表征能力
跳跃连接(Skip Connection)
层标准化(Layer Normalize):$ \gamma, \beta$持续训练,对某一词向量调整(统一量纲、移动数据分布区间到激活函数高梯度范围),加快模型收敛速度,使模型更稳定;解决小批量训练时,小批量无法体现总体特征的问题;
$$ y_i = \gamma \cdot \left( \frac{x_i - \mu_L}{\sqrt{\sigma_L^2 + \epsilon}} \right) + \beta \\ \mu_L = \frac{1}{m}\sum_{i=1}^m x_i \quad \sigma_L^2 = \frac{1}{m}\sum_{i=1}^m (x_i - \mu_L)^2 \quad \epsilon > 0 \quad \gamma, \beta $$
解码器(Decoders):根据编码器的$\text{Keys}/\text{Values}$向量,以当前输入$\text{Querys}$,自回归以token:BEGIN、END生成文本序列
- 掩码多头注意力机制(Masked Multi-Headed Attention):利用$\text{Look-Ahead Mask}$矩阵抹去相似度矩阵中$\text{Querys}$先于$\text{Keys}$部分的相似度
- 交互多头注意力机制(Interactive Multi-Headed Attention):编码器输出$\text{Keys}/\text{Values}$向量,掩码多头注意力机制层输出$\text{Values}$向量,以这些作为为输入,确定焦点编码器
扩展:复制机制、引导注意力机制、beam search、随机噪声、强化学习、鲁棒样本
优点:可小批量,可并行化,复杂模型弹性大,小数据集过拟合,大数据集损失低(对比简单模型弹性小,小数据集训练快,大数据集损失大)
缺点:超参敏感、优化困难
GPT
GPT 系列论文精读:从 GPT-1 到 GPT-4_gpt 论文-CSDN博客
基于大规模文本语料库的自回归生成式预训练语言模型,其核心是基于 Transformer 架构的参数化概率分布,用于对token序列的生成进行建模
1.0
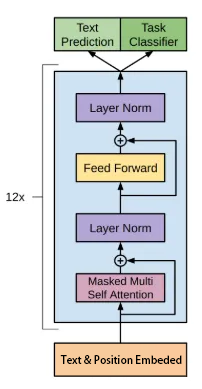
- 解码器堆叠(n * Decoders)
- “预训练-微调”范式(Pre-training + Fine-tuning)
2.0
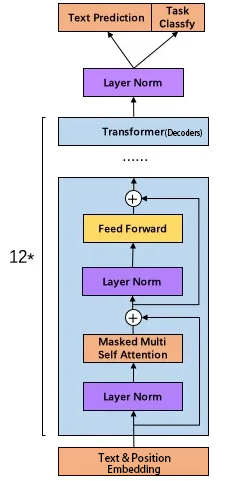
- 前置层归一化(Pre-LN)
3.0 -> ChatGPT
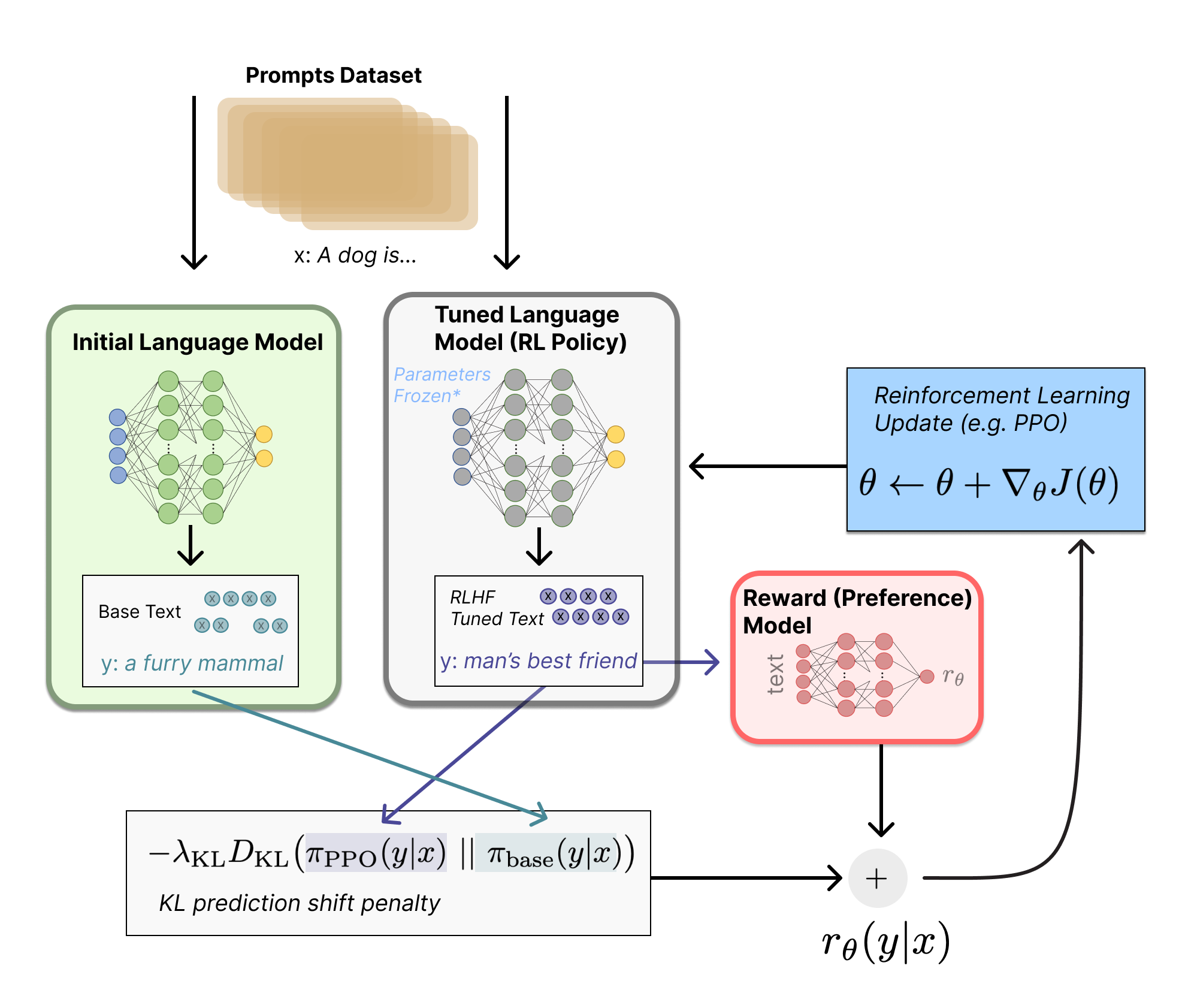
- 后训练(Post-Training)对齐
- 监督微调 (Supervised Fine-tuning, SFT): 使用高质量的指令和对话样本对预训练模型进行微调,使其初步具备遵循指令和进行对话的能力
- 人类反馈强化学习(Reinforcement Learning from Human Feedback, RLHF):基于人类对多个回答的排序数据,训练奖励模型以评估回答的有用性和安全性,利用奖励模型作为反馈,通过PPO最大化奖励,并通过拒绝采样选择最优样本进行迭代优化,持续提升模型性能
- 随机采样(Stochastic Sampling)
4.0
5.0
Llama
开源,基于大规模高质量公开语料,在相对较小的模型规模上实现了更长的上下文、更强的编码和推理能力
1
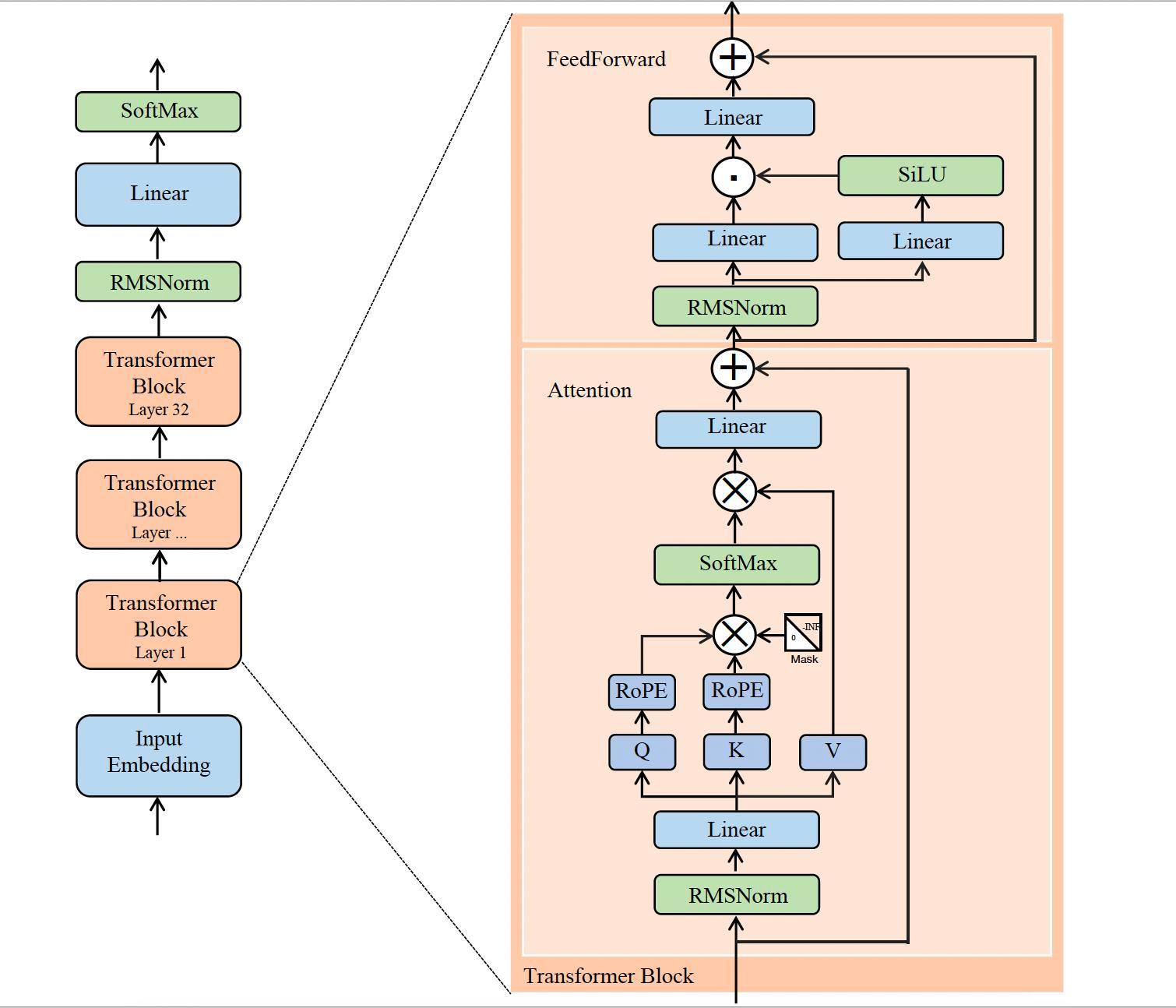
均方根标准化(RMSNorm):在每个子层输入前进行归一化,通过省略均值中心化步骤,仅依据向量元素的均方根进行缩放,从而降低了计算复杂度,同时有效维持了训练过程的稳定性
SwiGLU激活: 结合了 Swish 激活函数的平滑非线性和门控机制,增强了模型的表达能力,调整了 FFN 的隐藏层维度,以在引入门控参数的同时,大致保持 FFN 层的总参数量和计算量不变
旋转位置编码(RoPE):通过对 Query 和 Key 向量施加与位置相关的旋转操作,将相对位置信息有效融入自注意力计算中,增强了模型处理长序列和捕捉长距离依赖关系的能力
2
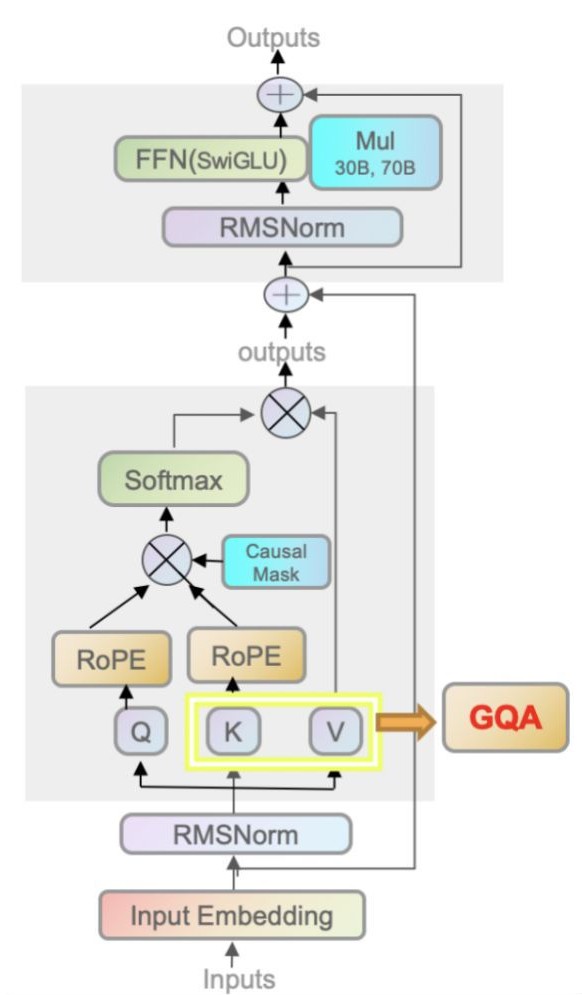
- 分组查询注意力 (GQA):允许多个查询头共享同一组键(Key)和值(Value)头,不影响模型性能的前提下显著减少了推理过程中 KV 缓存的内存占用和计算开销,从而提高了大模型的推理速度和部署效率
3
4
BART
- 五个训练任务:Token Masking、Sentence Permutation、Document Rotation、Token Deletion、Text Infilling,循序渐进激发模型潜能
GLM
对标 GPT,适配国产GPU,开源生态
BERT
DeepSeek
- MoE
Agent
智能体(Agent):大模型+工具插件+综合系统(类推荐系统)–>具备多模态输入理解、工具自主规划调用、长短期记忆维护以及任务序列执行能力。
- 检索增强(RA):从领域知识库(如搜索引擎)中检索相关信息,经筛选后用于增强大模型的生成效果与准确性。
- 提示词工程(prompt engineering):通过精心设计与优化输入至AI模型的文本指令,以提升其在特定任务上的表现。
- 输出解析器 (Output Parsers):将模型输出的原始文本转换为结构化数据格式,便于后续处理与应用。
应用方向:智能对话、图文生成、代码生成与辅助编程等。
Prompt Engineering
提示工程指南 | Prompt Engineering Guide
- Role: LLMs are more sensitive to the content at the beginning and end of a prompt. It narrows the problem domain and reduce ambiguity.
- Instructions: Provide a clear and explicit description of the task.
- Break down into subtasks.
- Chain-of-Thought (CoT): Request a step-by-step response or construct a chain-like procedure.
- Tree-of-Thought (ToT): Request multi-path reasoning or construct a branching procedure.
- Self-Consistency: Run the procedure multiple times and select the best outcome.
- Prompt Attack: Apply additional constraints via prompts on top of the task or via APIs from others on top of the input to prevent the LLM from generating unintended, harmful, or unauthorized behavior.
- Context, Examples, Input, and Output Format Descriptions…
==让大模型优化你的提示词!!!==
I want you to become my Expert Prompt Creator. Your goal is to help me craft the best possible prompt for my needs. The prompt you provide should be written from the perspective of me making a request to ChatGPT. Please keep in mind that the final prompt will be used directly with ChatGPT. The process is as follows:
- Your response must include the following sections:
- Prompt: {Provide the best possible prompt according to my request.}
- Critique: {Provide a concise paragraph on how to improve the prompt. Be very critical in your response.}
- Questions: {Ask any questions pertaining to what additional information you need from me to improve the prompt (max of 3 questions). If the prompt needs more clarification or details in certain areas, ask questions to get more information to include.}
- I will then answer your questions. You must incorporate my answers into the next revised prompt using the same format. We will continue this iterative process with me providing additional information and you updating the prompt until it is perfected.
Remember, the prompt we are creating should be written from the perspective of me making a request to ChatGPT. Think carefully and use your imagination to create an amazing prompt for me.
Your first response should only be a greeting and to ask me what the prompt should be about.
提示词相关网站:
- PromptBase | Prompt Marketplace: Midjourney, ChatGPT, Veo, FLUX & more.
- f/awesome-chatgpt-prompts
- Hub - LangSmith
Fine-tuing
Direction-Tuning
需要考虑模型参数量,显存是否足够、算力是否足够、数据量是否足够…
Prefix-Tuning
在模型的输入或者隐层添加k个额外可训练的前缀tokens,只训练这些前缀参数
Adapter-Tuning
将较小的神经网络层或模块(adapter)插入预训练模型的每一层,下游任务微调时只训练adapter参数
LoRA
通过学习小参数的低秩矩阵来近似近似模型权重矩阵的参数更新。下游任务微调时只训练低秩矩阵参数