GPUs
大模型配置硬件参考自查表 - AI全书大模型配置硬件参考自查表 - AI全书
参数规模:模型参数数量,以十亿(B)为单位,该单位大小与 GB 近似
- 轻量级(1-7B):适合个人电脑
- 中量级(14-32B):需要高性能显卡
- 重量级(70B+):需专业服务器
数据位宽:模型参数精度,权衡训练速度和显卡资源
精度类型 字节/参数 适用场景 备注 FP32 4字节 混合训练 最高精度 FP16 2字节 推理部署 平衡选择 BF16 2字节 训练加速 专为AI优化 FP8 1字节 边缘设备 最大压缩 模型量化:模型参数压缩,通过牺牲模型精度,减小显存需求,常用于推理
- CV 任务:INT8
- NLP 任务:FP16
- 大模型任务:混合INT8/FP16
矩阵运算:硬件加速、算法加速、线程并行
- 模型过大:流水线并行
- 矩阵过大:张量并行
- 数据量过大:数据并行
对模型大小为$S$,量化后模型大小为$S'$,参数数量为$N$,每个参数的字节数为$B$,量化开销系数为$k \in [1.1, 1,2]$,中间结果大小
$$ S = N \times B $$$$ S' = N \times B' \times k $$训练时显存开销包括模型参数占用、梯度参数占用、优化器参数占用、中间结果和CUDA kernel占用;推理时显存开销包括模型参数占用、中间结果和CUDA kernel占用
| 阶段 | 近似显存占用(相对于原始模型大小) |
|---|---|
| 训练 (Training) | 12 ~ 20 倍 |
| 全参数微调 (Full Fine-Tuning) | 8 ~ 15 倍 |
| LoRA微调 (LoRA Fine-Tuning) | 1.2 ~ 2 倍 |
| 推理 (Inference) | 1.2 ~ 5 倍 |
Tasks
- 预测:经深度网络传播至单个神经元,以其标量输出作为预测结果
- 单标签分类:以 FFN 将上游特征传播至【标签数】个神经元上,经 softmax 转换为概率分布,取概率最高的标签作为分类结果
- 多标签分类:以 FFN 将上游特征传播至【标签数】个神经元上,经 sigmoid 计算各标签概率,取超过设定阈值的标签作为分类结果
- 文本|语音翻译:采用 Transformer 架构,编码器将源语言语句编码为语义表示,解码器依据该表示自回归生成目标语言词序列(内部同样经 softmax 转换为词汇表概率分布,取概率最高的词汇作为该轮预测结果)
- 文本生成:原任务转化为基于上下文的下一个词预测问题,一般采用 Transformer-Decoder 架构
- QA:合并 Question 和 Answer 为单个词序列,原任务转化为文本生成问题
- 涌现:当模型参数量(层数、宽度、token维度、隐藏层维度)和数据量(上下文长度、词汇表大小)疯狂扩大,无需改变此基础结构,会产生更强大的学习能力
- 套壳:利用闭源大模型API生成训练数据,预处理后全监督微调开源预训练模型,并用闭源大模型API评估训练效果
- 多模态:使用不同的编码器将不同模态的信息分别转换为向量表示, 模型学习不同模态信息之间的对应关系实现模态信息对齐, 将对齐后的信息融合到一个统一的表示中,以便进行后续的推理和决策。本质上还是nlp原理
- 强化学习:以奖励函数构建损失函数,引导反向传播
Experiences
模型训练三大件:
数据(数据清洗【异常、NULL】、数据分布【多样化、归一化、正则化】、数据增强【翻转、裁剪】)、模型(激活函数、损失函数【正则化惩罚项】、优化器、学习率、复杂度【dropout】)、训练方法(批次大小、训练轮次、权重初始化)
处理过拟合|泛化能力:
降低模型复杂度、增加数据量、大批次、噪声
处理梯度消失|梯度爆炸|收敛速度:
梯度裁剪、残差网络、权重初始化、数据归一化、优化器
大模型输出的**“包含”或“过滤”**:
提示词组件,通过添加到消息中实现;RAG技术,通过限制知识库范围实现;基于规则,通过加载JSON进行后处理实现
五个循序渐进预训练任务:
Token掩码、句子重排、文本旋转、Token删除、文本填充
API
Server
Client
transmission
- 流式:服务器逐块(逐词或逐句)生成内容,并立即将每个新生成的块返回给客户端。客户端可以几乎实时地看到内容逐渐出现
- 非流式:服务器一次性生成完整的内容,然后一次性返回给客户端。客户端需要等待整个生成过程完成才能看到结果
sdk
- openai-python
- python_requests
- CLI
- curl
role
- system:设定对话的背景、规则、身份和整体行为准则。这是给模型的“内部工作指令”
- user:代表人类用户的输入。这是模型需要回应、处理或遵循的指令、问题或陈述
- assistant:代表模型自己之前做出的回复。这是对话历史中模型自身的输出记录,也可作为模型的初始指引
deep thinking
| 特性 | 深度思考模式(开启) | 普通模式(不开启) |
|---|---|---|
| 响应速度 | 慢。需要时间进行逐步推理。 | 快。直接生成最可能的回答。 |
| 回答形式 | 包含详细的推理步骤和过程,最后给出结论。 | 通常是直接的、最终的答案或总结。 |
| 准确性 | 在复杂任务上更高,容错率低。 | 在复杂任务上相对较低,容易“想当然”。 |
| 透明度 | 高。你可以看到模型的“思考”链条。 | 低。你得到一个答案,但不知道它怎么来的。 |
| 适用场景 | 数学计算、逻辑谜题、代码调试、复杂分析、学术研究、制定计划等。 | 简单问答、内容摘要、创意写作、日常对话等。 |
| 资源消耗 | 高。消耗更多的计算资源和Token。 | 低。响应高效,成本更低。 |
temperature
控制模型输出随机性与创造性,数值越低(如0.1-0.5),生成结果越确定、保守且可预测,模型倾向于选择概率最高的词汇;数值越高(如0.7-1.0以上),输出越随机、多样且富有创意,模型会赋予低概率词汇更多机会,但可能降低连贯性
| 温度范围 | 模型行为特点 | 最佳适用场景 | 需避免的场景 |
|---|---|---|---|
| 很低 (0.1 - 0.3) | 高度确定、一致、重复 | 代码生成、事实问答、技术翻译、精确摘要 | 创意写作、聊天机器人(会显得像机器人) |
| 中低 (0.4 - 0.7) | 平衡、可靠、稍带变化 | 通用助手、内容创作初稿、商务邮件、分析报告 | 需要高度创造性的任务 |
| 中高 (0.8 - 1.0) | 富有创意、多样、有趣 | 创意写作、营销文案、对话式AI、头脑风暴 | 事实性任务(可能导致幻觉) |
| 很高 (1.0+) | 高度随机、不可预测、冒险 | 写诗、生成艺术创意、探索性想法、实验性写作 | 任何需要可靠性和事实准确性的任务 |
Agent
模型能力:多模态输入理解、长短期记忆、自主规划、工具调用、任务序列执行
- [基座模型](# Base Model):在开发AI应用时,从众多开源或闭源的基础大模型中,挑选一个作为基石
- [提示词工程](# Prompt Engineering):通过精心设计与优化输入至AI模型的文本指令,以提升其在特定任务上的表现
- [检索增强](# RAG):从领域知识库(如搜索引擎)中检索相关信息,经筛选后用于增强大模型的生成效果与准确性
- 输出解析器:将模型输出的原始文本转换为结构化数据格式,如JSON,便于后续处理与应用
- [工具调用](# Tools):为模型提供API工具的“功能定义”,并搭建一个让模型能够主动发出指令、系统负责执行、结果供给参考的框架
- [微调](# Fine-tuing):用特定的专业数据集(指令对话样本)继续训练预训练模型,把它变成一个特定领域的专家
- [强化学习](# RL):对已经预训练和微调过的模型利用奖励函数或模型进行“精修”和“对齐”
Base Model
当前大模型指基于大规模文本语料库的自回归生成式语言模型,通过对token序列的参数化概率分布随机采样实现;
基座模型的选择,需要考虑模态、生态开源或闭源、规模与成本、专业能力匹配,现有的大模型不计其数,可以借助大模型检索能力推荐;
经过评估在特定任务上表现不错的基座模型,通过有针对性地投入高质量数据和算力,能够激发其在该任务上的潜力,最终锻造出一个在该领域表现卓越的专业化模型,否则不适合作为基座模型;
GPT
Transformer 解码器堆叠架构
Llama
开源,规模相对较小
Qwen
GLM
开源生态,国产GPU适配
InterVL
DeepSeek
BERT
Tech
MoEs
混合专家模型,为由多个单独网络(“专家”)组成的系统建立一个监管机制,每个“专家”处理训练样本的不同子集,专注于输入空间的特定区域;设置门控网络|路由分配每个“专家”的权重或决定哪些Token被发送到哪些“专家”;在训练过程中,这些专家和门控网络都同时接受训练,以优化它们的性能和决策能力。
组件专家:允许将 MoE 嵌入到多层网络中的某一层,如 Transformer 的 FFN
条件计算:基于输入Token动态激活或停用网络组件
负载均衡:门控算法抑制Token不均匀分配和“专家”训练不均匀
- 专家容量:Token处理阈值,”专家“都达到处理上限后,Token通过残差溢出到下一层
- 稀疏稳定性:容量因子、dropout
- 专业程度:编码器“专家”各司其职;解码器“专家”较低专业化程度。
并行计算:MoE 层在不同设备间共享,而其他所有层则在每个设备上复制
万亿参数:极高模型规模,节省计算资源,高效预训练,高速推理
微调策略:稀疏部分正则化;负载均衡算法;MoE层冻结;较小批次大小和较大学习率
缺点:显存消耗高;(稀疏部分)易过拟合,泛化能力不足,微调困难;不适合重理解任务
优点:适合知识密集型任务;从指令微调中获益;多任务学习
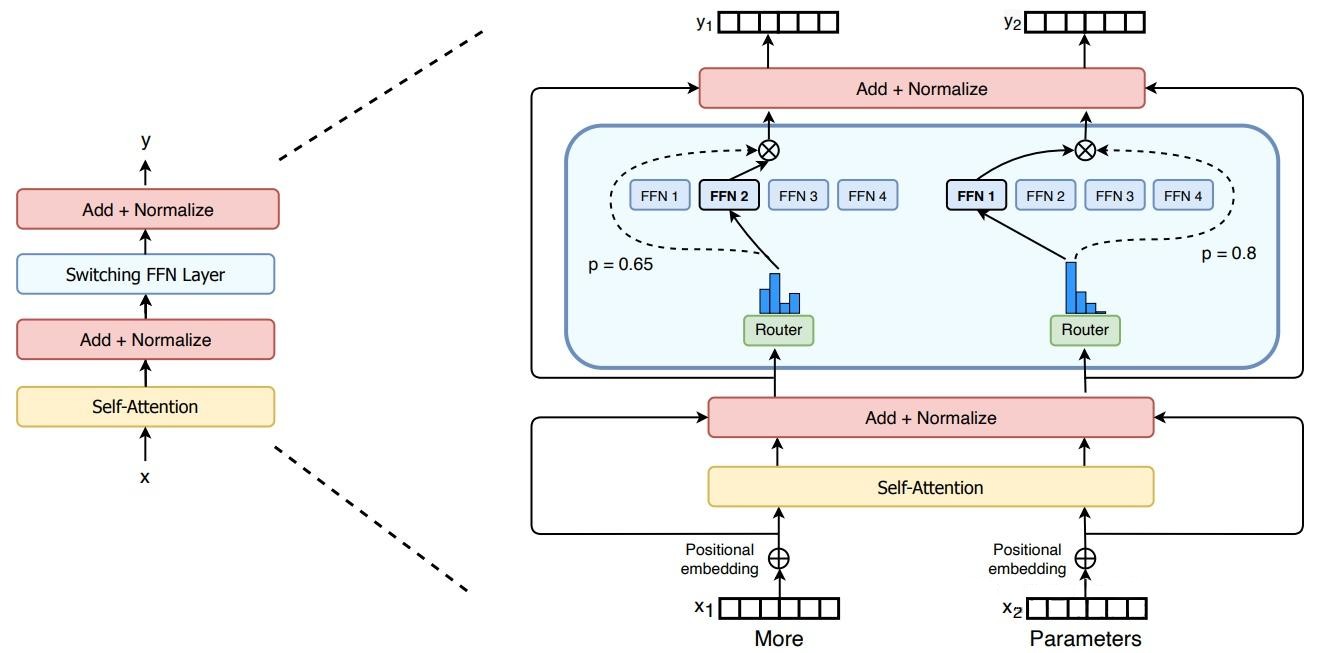
- 共享专家(Shared Expert):所有 tokens 都会经过的共享专家,每个 token 会用计算的 Router 权重,来选择 topK 个专家,然后和共享的专家的输出一起加权求和;捕捉通用、全局的特征信息,减少不同专家间的知识冗余,提升计算效率
Pre-LN
前置层归一化
RMSNorm
均方根标准化,在每个子层输入前进行归一化,通过省略均值中心化步骤,仅依据向量元素的均方根进行缩放,从而降低了计算复杂度,同时有效维持了训练过程的稳定性
SwiGLU
激活函数, 结合了 Swish 激活函数的平滑非线性和门控机制,增强了模型的表达能力,调整了 FFN 的隐藏层维度,以在引入门控参数的同时,大致保持 FFN 层的总参数量和计算量不变
RoPE
旋转位置编码,通过对 Query 和 Key 向量施加与位置相关的旋转操作,将相对位置信息有效融入自注意力计算中,增强了模型处理长序列和捕捉长距离依赖关系的能力
GQA
分组查询注意力,允许多个查询头共享同一组键(Key)和值(Value)头,不影响模型性能的前提下显著减少了推理过程中 KV 缓存的内存占用和计算开销,从而提高了大模型的推理速度和部署效率
Prompt Engineering
提示工程指南 | Prompt Engineering Guide
LLMs对提示词开头和结尾的内容更敏感,可收缩问题域,减少二义性
- 开头:设定角色和任务
- 结尾:规定输出格式
提供清晰明确的任务描述,模糊的指令导致模糊的输出
清晰明确:使用动作动词(撰写、总结、分类、翻译、生成、推理)
分解子任务:用“第一步、第二步…”梳理任务逻辑
思维链(CoT):指令要求“逐步推理”触发,或者构建链式程序
思维树(ToT):指令要求“多分支推理”触发,或者构建树式程序
一致性优化:指令要求”给出多个推理过程并选择最佳结果“,或者构建投票或权重程序
上下文背景 或 RAG:分块向量化入库、数据检索,重排过滤注入
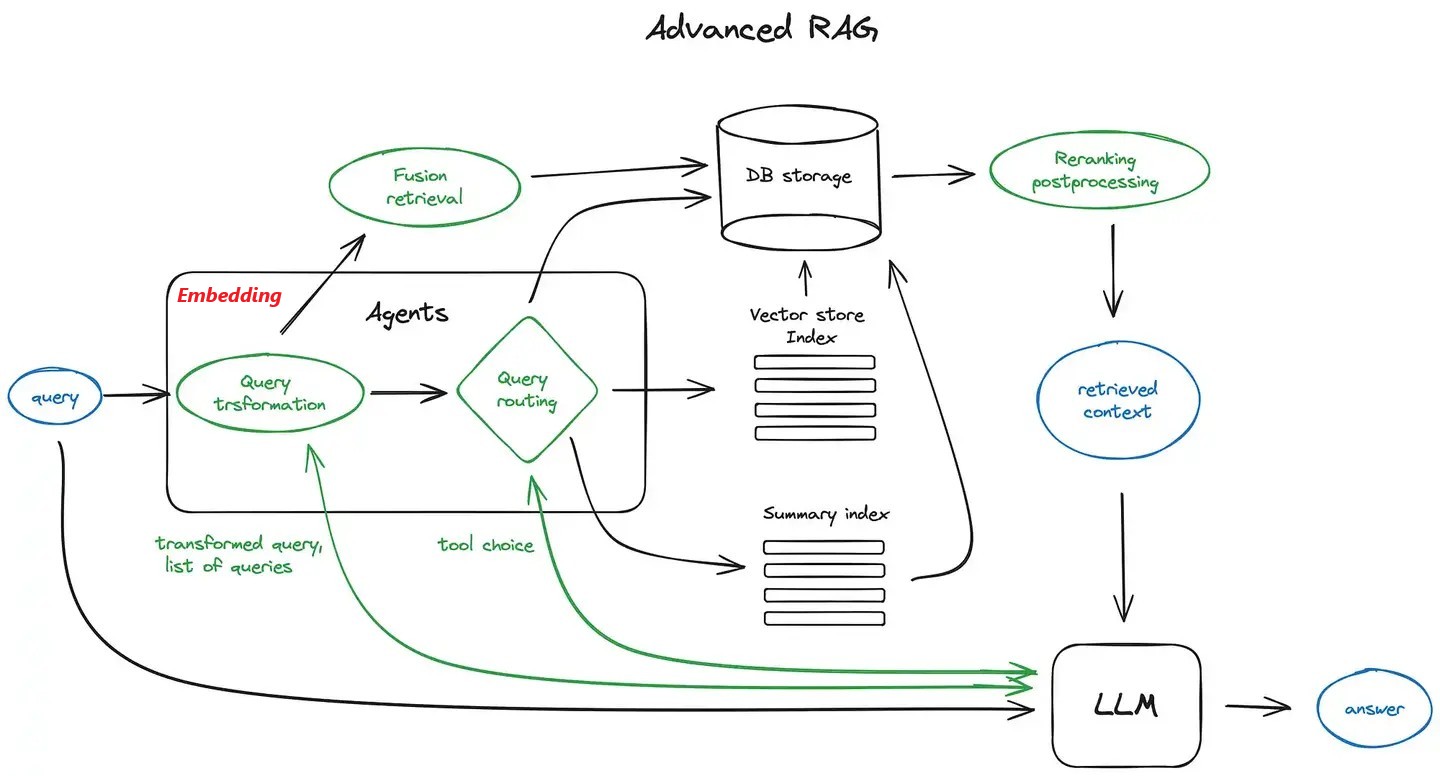
提供样本输入输出示例
附加主提示词或其他功能模块强约束防止有害或未经授权的行为
==让大模型优化你的提示词!!!==
I want you to become my Expert Prompt Creator. Your goal is to help me craft the best possible prompt for my needs. The prompt you provide should be written from the perspective of me making a request to [ChatGPT]. Please keep in mind that the final prompt will be used directly with [ChatGPT]. The process is as follows:
- Your response must include the following sections:
- Prompt: {Provide the best possible prompt according to my request.}
- Critique: {Provide a concise paragraph on how to improve the prompt. Be very critical in your response.}
- Questions: {Ask any questions pertaining to what additional information you need from me to improve the prompt (max of 3 questions). If the prompt needs more clarification or details in certain areas, ask questions to get more information to include.}
- I will then answer your questions. You must incorporate my answers into the next revised prompt using the same format. We will continue this iterative process with me providing additional information and you updating the prompt until it is perfected.
Remember, the prompt we are creating should be written from the perspective of me making a request to [ChatGPT]. Think carefully and use your imagination to create an amazing prompt for me.
Your first response should only be a greeting and to ask me what the prompt should be about.
我希望您能担任我的专业提示词创建专家。您的目标是帮助我根据需求打造最优质的提示词。您提供的提示词应当从我向[ChatGPT]提出请求的视角来撰写。请注意,最终完成的提示词将直接用于[ChatGPT]交互。流程如下:
您的回复必须包含以下部分:
- 提示词: {根据我的需求提供最优提示词方案}
- 优化建议: {用批判性视角提供改进建议,以简练段落说明如何提升提示词质量}
- 追问: {提出最多3个关键问题,询问需要哪些补充信息来优化提示词。若提示词某些方面需要更详尽的说明,应通过提问获取更多细节}
我将回答您的提问。您必须将我的回答整合到新的修订版提示词中,并保持相同格式。我们将持续这个迭代过程:我提供补充信息,您则相应更新提示词,直至达到完美效果。
请谨记:我们共同创建的提示词必须从我向[ChatGPT]提出请求的视角撰写。请充分发挥创造力和思考力,为我打造卓越的提示词方案。
您的首次回复应当仅为问候语,并询问我希望提示词的主题方向。
- 参考提示词相关网站:
RAG
关键词:LangChain 和 LlamaIndex
Tools
关键词:ToolUniverse 和 MCP
Fine-tuing
Direction-Tuning
需要考虑模型参数量,显存是否足够、算力是否足够、数据量是否足够…
Prefix-Tuning
在模型的输入或者隐层添加k个额外可训练的前缀tokens,只训练这些前缀参数
Adapter-Tuning
将较小的神经网络层或模块(adapter)插入预训练模型的每一层,下游任务微调时只训练adapter参数
LoRA
通过学习小参数的低秩矩阵来近似近似模型权重矩阵的参数更新。下游任务微调时只训练低秩矩阵参数
RL
人类反馈强化学习(Reinforcement Learning from Human Feedback, RLHF)
基于人类对多个回答的排序数据,训练奖励模型以评估回答的有用性和安全性,利用奖励模型作为反馈,通过PPO最大化奖励,并通过拒绝采样选择最优样本进行迭代优化,持续提升模型性能